
[fusion_builder_container hundred_percent=”no” hundred_percent_height=”no” hundred_percent_height_scroll=”no” hundred_percent_height_center_content=”yes” equal_height_columns=”no” menu_anchor=”” hide_on_mobile=”no” class=”” id=”” background_color=”” background_image=”” background_position=”left top” background_repeat=”no-repeat” fade=”no” background_parallax=”none” enable_mobile=”no” parallax_speed=”0.3″ video_mp4=”” video_webm=”” video_ogv=”” video_url=”” video_aspect_ratio=”16:9″ video_loop=”yes” video_mute=”yes” video_preview_image=”” border_size=”0px” border_color=”” border_style=”solid” margin_top=”” margin_bottom=”” padding_top=”4%” padding_right=”” padding_bottom=”” padding_left=””][fusion_builder_row][fusion_builder_column type=”1_6″ layout=”1_6″ spacing=”0px” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”medium-visibility,large-visibility” class=”” id=”” background_color=”” background_image=”” background_position=”left top” undefined=”” background_repeat=”no-repeat” hover_type=”none” border_size=”0″ border_color=”” border_style=”solid” border_position=”all” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” margin_top=”” margin_bottom=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”no”][/fusion_builder_column][fusion_builder_column type=”2_3″ layout=”2_3″ spacing=”0px” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”no” class=”” id=”” background_color=”” background_image=”” background_position=”left top” undefined=”” background_repeat=”no-repeat” hover_type=”none” border_size=”0″ border_color=”” border_style=”solid” border_position=”all” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” margin_top=”” margin_bottom=”” animation_type=”” animation_direction=”left” animation_speed=”0.1″ animation_offset=”” last=”no”][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” class=”” id=””]
[fusion_dropcap color=”” boxed=”yes” boxed_radius=”50%” class=”” id=””]I[/fusion_dropcap]
In your research for Search Engine Optimization (SEO) strategies, you will most likely come up with an overwhelming amount of information. Some of it might even be contradictory at times. The fact of the matter is that search engine’s (i.e. Google, Bing, Yahoo!, Baidu) algorithms are a very well kept secrets. Although there is some documentation regarding how search engine indexing and ranking works, the best SEO execution strategies are best based testing and validating results.
Do not be fooled by companies trying to sell you services for SEO Optimization, as many are hoaxes and scams. Any one that tells you they will assure you the first SERP (Search Engine Results Page) spot is lying and misleading at least. Believe me, you can do much of this by yourself! Just take a bit of time to research about SEO!
[/fusion_text][fusion_separator style_type=”none” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” class=”” id=”” sep_color=”” top_margin=”10px” bottom_margin=”” border_size=”” icon=”” icon_circle=”” icon_circle_color=”” width=”” alignment=”center” /][fusion_text columns=”” column_min_width=”” column_spacing=”” rule_style=”default” rule_size=”” rule_color=”” class=”” id=””]
Don’t be discouraged!
Nothing to worry about! This is great starting point, but know it’s just the beginning. In order to narrow down your initial steps, I have compiled a short list of five in-page elements, two off-page elements and three free tools that will focus your initial SEO efforts. Throughout this tutorial, this website will be used as an example of the elements we will explore. Let’s get started!
[/fusion_text][fusion_separator style_type=”none” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” class=”” id=”” sep_color=”” top_margin=”10px” bottom_margin=”” border_size=”” icon=”” icon_circle=”” icon_circle_color=”” width=”” alignment=”center” /][fusion_checklist icon=”” iconcolor=”” circle=”” circlecolor=”” size=”” divider=”” divider_color=”” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” class=”” id=””][fusion_li_item icon=””]
Page Titles
The Page Title of your website or landing page should be one of the most important aspects of your initial SEO strategy. This is literally your headline. In order to drive this point home, I will make this very visual for you to understand. Below is the Search Engine Results Page (SERP) for my website guspecunia.com from provided by Google followed by the top level HTML code for page title:
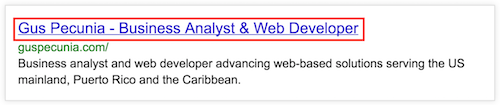
[fusion_syntax_highlighter theme=”” language=”html” line_numbers=”” line_wrapping=”” copy_to_clipboard=”” copy_to_clipboard_text=”Copy to Clipboard” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” class=”” id=”” font_size=”” border_size=”” border_color=”” border_style=”” background_color=”” line_number_background_color=”” line_number_text_color=”” margin_top=”” margin_left=”” margin_bottom=”” margin_right=””]PCFET0NUWVBFIGh0bWw+CjxodG1sIGxhbmc9ImVuIj4KPGhlYWQ+CjxtZXRhIGNoYXJzZXQ9InV0Zi04Ij4KPHRpdGxlPiBHdXMgUGVjdW5pYSAtIEJ1c2luZXNzIEFuYWx5c3QgJiBXZWIgRGV2ZWxvcGVyIDwvdGl0bGU+[/fusion_syntax_highlighter]
There is a term in SEO that you will hear forever again: KEYWORDS! Although I go through the concept more in detail in other posts, I want you to concentrate in how can you leverage the title of your page with how you think people would go search for your content online. For starters, you should keep a couple of things in mind. First, think of a title for your page that has a brand element and a short description of the substance in your context. Second, especially if you are optimizing for written content (i.e. blogs, newsletters, posts, etc.), think of that short description as an eye catcher. Similarly think of many posts that we come across online: “The 10 Must Haves”, “Top 25 Scary Movies of 2016”, “Three ways for cooking eggs”… People have come to use these types of attention grabbing page titles to capture viewers into their websites. I am not necessarily suggesting making a list of things but just know that there is a strategy running behind this page as well.
[/fusion_li_item][fusion_li_item icon=””]
Meta Descriptions
After determining a good page title for your website, the next step would be to establish the page’s description or meta description. If your page title was your headline, this would be your supporting tag line. Make sure to include information relevant to the content as a continuation of your page title. Below is the same SERP screenshot from above marking in red where your page’s meta description will appear, followed by the relevant HTML code:
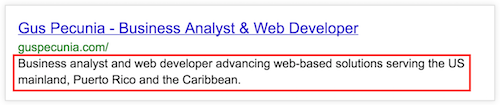
[fusion_syntax_highlighter theme=”” language=”html” line_numbers=”” line_wrapping=”” copy_to_clipboard=”” copy_to_clipboard_text=”Copy to Clipboard” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” class=”” id=”” font_size=”” border_size=”” border_color=”” border_style=”” background_color=”” line_number_background_color=”” line_number_text_color=”” margin_top=”” margin_left=”” margin_bottom=”” margin_right=””]PCFET0NUWVBFIGh0bWw+CjxodG1sIGxhbmc9ImVuIj4KPGhlYWQ+CjxtZXRhIGNoYXJzZXQ9InV0Zi04Ij4KPHRpdGxlPiBHdXMgUGVjdW5pYSAtIEJ1c2luZXNzIEFuYWx5c3QgJiBXZWIgRGV2ZWxvcGVyIDwvdGl0bGU+CjxtZXRhIG5hbWU9ICJkZXNjcmlwdGlvbiIgY29udGVudD0gIkJ1c2luZXNzIGFuYWx5c3QgYW5kIHdlYiBkZXZlbG9wZXIKYWR2YW5jaW5nIHdlYi1iYXNlZCBzb2x1dGlvbnMgc2VydmluZyB0aGUgVVMgbWFpbmxhbmQsIFB1ZXJ0byBSaWNvIGFuZAp0aGUgQ2FyaWJiZWFuLiI+Cg==[/fusion_syntax_highlighter]
[/fusion_li_item][fusion_li_item icon=””]
Headings
The heading element is one of much discussion among the SEO community. There is a lot of debate about the impact of way too many <h1's> tags and also over-weighting specific <h#'s>(heading HTML tags) and how it affects SEO and SERP’s. Keep this discussion in the back of your mind but focus on delivering a structure to the webpage that makes sense. Think of it as doing a bulleted list by order of magnitude. Use your tags for the highest level of content that your page delivers (title, main subject) and subsequently use the other <h2/h3/h4's> as sub-themes within the <h1's> tags of content delivery.
[/fusion_li_item][fusion_li_item icon=””]
Canonical Tags
In order to refrain search engines from identifying duplicate content it is very important to include the canonical tag code for each of your webpages. The reason behind this is that sometimes search engines will count as two pages when it identifies, for example, guspecunia.comand guspecunia.com/.To prevent this the html code has to carry a canonical tag to inform the search engine that what it is considering as two pages is really one webpage. When setting a canonical tag we are telling the search engine that this is the preferred address for the content that we are providing. Take a look at the example below for the necessary code:
[fusion_syntax_highlighter theme=”” language=”x-sh” line_numbers=”” line_wrapping=”” copy_to_clipboard=”” copy_to_clipboard_text=”Copy to Clipboard” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” class=”” id=”” font_size=”” border_size=”” border_color=”” border_style=”” background_color=”” line_number_background_color=”” line_number_text_color=”” margin_top=”” margin_left=”” margin_bottom=”” margin_right=””]PCFET0NUWVBFIGh0bWw+CjxodG1sIGxhbmc9ImVuIj4KPGhlYWQ+CjxtZXRhIGNoYXJzZXQ9InV0Zi04Ij4KPHRpdGxlPiBHdXMgUGVjdW5pYSAtIEJ1c2luZXNzIEFuYWx5c3QgJiBXZWIgRGV2ZWxvcGVyIDwvdGl0bGU+CjxtZXRhIG5hbWU9ICJkZXNjcmlwdGlvbiIgY29udGVudD0gIkJ1c2luZXNzIGFuYWx5c3QgYW5kIHdlYiBkZXZlbG9wZXIKYWR2YW5jaW5nIHdlYi1iYXNlZCBzb2x1dGlvbnMgc2VydmluZyB0aGUgVVMgbWFpbmxhbmQsIFB1ZXJ0byBSaWNvIGFuZAp0aGUgQ2FyaWJiZWFuLiI+CjxsaW5rIHJlbD0iY2Fub25pY2FsIiBocmVmPSJodHRwczovL2d1c3BlY3VuaWEuY29tIi8+Cg==[/fusion_syntax_highlighter]
[/fusion_li_item][fusion_li_item icon=””]
Images
The important aspect of image coding in SEO is in the "alt" attribute or alternate text specific name. This attribute has two purposes: substitutes the image if the image cannot be resolved when delivering the page and it also serves as text information tied to the image. For search engine robots or crawlers, alternate text is what they record when they come across an image in your webpage. It is very important for all the images in your webpage to have “alt” attribute in order to make web crawlers understand that the image is relevant to the context and therefore increasing your search engine visibility. Take a look a the code below for an example of the HTML <... alt="Image Name".../> attribute:
[fusion_syntax_highlighter theme=”” language=”x-sh” line_numbers=”” line_wrapping=”” copy_to_clipboard=”” copy_to_clipboard_text=”Copy to Clipboard” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” class=”” id=”” font_size=”” border_size=”” border_color=”” border_style=”” background_color=”” line_number_background_color=”” line_number_text_color=”” margin_top=”” margin_left=”” margin_bottom=”” margin_right=””]PGEgaHJlZj0iaHR0cDovL3RoZXZzamhvdGVsLmNvbSIgdGFyZ2V0PSJfYmxhbmsiPgo8aW1nIGNsYXNzPSJpbWctcmVzcG9uc2l2ZSIgc3JjPSJhc3NldHMvaW1nL3ZzamxvZ28ucG5nIiBhbHQ9IlRoZSBWU0ogSG90ZWwiCiB0YXJnZXQ9Il9ibGFuayI+PC9hPiAK[/fusion_syntax_highlighter]
[/fusion_li_item][fusion_li_item icon=””]
Robots.txt
As owner of your website use the robots.txt file to give web crawlers or robots instructions on how to navigate your website. When a web crawler scans your website, the first thing it does is to look at your robots.txt file in order to know where to look and where not to do so. There are two important attributes to this file: User-agent: * which means that this section applies to all robots, and Disallow: / which tells the robots it should not visit any page or asset followed after the Disallow: / statement
[fusion_syntax_highlighter theme="" language="txt" line_numbers="" line_wrapping="" copy_to_clipboard="" copy_to_clipboard_text="Copy to Clipboard" hide_on_mobile="small-visibility,medium-visibility,large-visibility" class="" id="" font_size="" border_size="" border_color="" border_style="" background_color="" line_number_background_color="" line_number_text_color="" margin_top="" margin_left="" margin_bottom="" margin_right=""]IyByb2JvdHMudHh0IGZvciBodHRwczovL2d1c3BlY3VuaWEuY29tLwoKVXNlci1hZ2VudDogKgpEaXNhbGxvdzogL2Fzc2V0cw==[/fusion_syntax_highlighter]
I want to be clear about something, do not think that disallowing robots to visit a specific page means that this page is not accessible. I will be accessible! Therefore do not try to hide pages or assets in your
robots.txtfile! Copy and paste the example above in your editor and save it as robots.txt file. You want to drop this close to your index.html (as in opposed to buried in your website). The file should be accessible through:http://www.yourwebsite.com/robots.txt.
[/fusion_li_item][fusion_li_item icon=””]
Sitemaps
Sitemaps are the road map to your webpage and web crawlers use it to better understand the structure of your website while indexing it for search engines. Look at the example code below. Copy and edit it according to your website’s needs. There are various terms that you will get familiarized when working with sitemaps. These are: – webpage location (i.e. https://guspecunia.com), – last date of modifications to the page, – how often you make changes to the page, and – think of it as the weighted importance of the page. Click here if you want to download the .xml file containing the sitemap and edit it in your code editor.
[fusion_syntax_highlighter theme=”” language=”xml” line_numbers=”” line_wrapping=”” copy_to_clipboard=”” copy_to_clipboard_text=”Copy to Clipboard” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” class=”” id=”” font_size=”” border_size=”” border_color=”” border_style=”” background_color=”” line_number_background_color=”” line_number_text_color=”” margin_top=”” margin_left=”” margin_bottom=”” margin_right=””]PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0iVVRGLTgiPz4KCjx1cmxzZXQgeG1sbnM9Imh0dHA6Ly93d3cuc2l0ZW1hcHMub3JnL3NjaGVtYXMvc2l0ZW1hcC8wLjkiPgo8dXJsPgo8bG9jPmh0dHA6Ly93d3cuZXhhbXBsZS5jb208L2xvYz4KPGxhc3Rtb2Q+WVlZLU1NLUREPC9sYXN0bW9kPgo8Y2hhbmdlZnJlcT5EYWlseTwvY2hhbmdlZnJlcT4KPHByaW9yaXR5PjEuMDwvcHJpb3JpdHk+CjwvdXJsPgo8dXJsPgo8bG9jPmh0dHA6Ly93d3cuZXhhbXBsZS5jb20vcGFnZTEuaHRtbDwvbG9jPgo8bGFzdG1vZD5ZWVktTU0tREQ8L2xhc3Rtb2Q+CjxjaGFuZ2VmcmVxPkRhaWx5PC9jaGFuZ2VmcmVxPgo8cHJpb3JpdHk+MC45PC9wcmlvcml0eT4KPC91cmw+Cjx1cmw+Cjxsb2M+aHR0cDovL3d3dy5leGFtcGxlLmNvbS9wYWdlMi5odG1sPC9sb2M+CjxsYXN0bW9kPllZWS1NTS1ERDwvbGFzdG1vZD4KPGNoYW5nZWZyZXE+V2Vla2x5PC9jaGFuZ2VmcmVxPgo8cHJpb3JpdHk+MC44PC9wcmlvcml0eT4KPC91cmw+Cjx1cmw+Cjxsb2M+aHR0cDovL3d3dy5leGFtcGxlLmNvbS9wYWdlMy5odG1sPC9sb2M+CjxsYXN0bW9kPllZWS1NTS1ERDwvbGFzdG1vZD4KPGNoYW5nZWZyZXE+V2Vla2x5PC9jaGFuZ2VmcmVxPgo8cHJpb3JpdHk+MC44PC9wcmlvcml0eT4KPC91cmw+Cjx1cmw+Cjxsb2M+aHR0cDovL3d3dy5leGFtcGxlLmNvbS9wYWdlNC5odG1sPC9sb2M+CjxsYXN0bW9kPllZWS1NTS1ERDwvbGFzdG1vZD4KPGNoYW5nZWZyZXE+TW9udGhseTwvY2hhbmdlZnJlcT4KPHByaW9yaXR5PjAuNTwvcHJpb3JpdHk+CjwvdXJsPgo8dXJsPgo8bG9jPmh0dHA6Ly93d3cuZXhhbXBsZS5jb20vcGFnZTUuaHRtbDwvbG9jPgo8bGFzdG1vZD5ZWVktTU0tREQ8L2xhc3Rtb2Q+CjxjaGFuZ2VmcmVxPk1vbnRobHk8L2NoYW5nZWZyZXE+Cjxwcmlvcml0eT4wLjU8L3ByaW9yaXR5Pgo8L3VybD4KPC91cmxzZXQ+Cg==[/fusion_syntax_highlighter]
[/fusion_li_item][fusion_li_item icon=””]
Google Analytics
Google Analytics is the world’s leading platform for online traffic analytics. The best thing about it is that it has a free tier service that is more than enough to start keeping track of your website’s traffic. For now, start getting comfortable with many of the terms you will come across through the analytics platform.
Click here to go Google Analytics Website
[/fusion_li_item][fusion_li_item icon=””]
Google Search Console
Google Search Console is another great SEO tool provided by Google that is completely free. It will help you and guide you with a huge array of documentation many other aspects that will increase your search engine visibility.
Click here to go Google Search Console Website
[/fusion_li_item][fusion_li_item icon=””]
SEO Quake Bar
If you are starting your journey into the SEO world this would be my best initial advice. First, do yourself a favor and download Google Chrome Browser and install it on your computer. Google Chrome has great development tools that your will want to have on your side. After you have installed Google Chrome, search and install the SEO Quake Bar Extension for Google Chrome, available in the Google Chrome Extensions Search Page.
[/fusion_li_item][/fusion_checklist][fusion_separator style_type=”none” hide_on_mobile=”small-visibility,medium-visibility,large-visibility” class=”” id=”” sep_color=”” top_margin=”30px” bottom_margin=”” border_size=”” icon=”” icon_circle=”” icon_circle_color=”” width=”” alignment=”center” /][/fusion_builder_column][fusion_builder_column type=”1_6″ layout=”1_6″ spacing=”0px” center_content=”no” link=”” target=”_self” min_height=”” hide_on_mobile=”medium-visibility,large-visibility” class=”” id=”” background_color=”” background_image=”” background_position=”left top” undefined=”” background_repeat=”no-repeat” hover_type=”none” border_size=”0″ border_color=”” border_style=”solid” border_position=”all” padding_top=”” padding_right=”” padding_bottom=”” padding_left=”” margin_top=”” margin_bottom=”” animation_type=”” animation_direction=”left” animation_speed=”0.3″ animation_offset=”” last=”no”][/fusion_builder_column][/fusion_builder_row][/fusion_builder_container]